
PythonによるWebスクレイピングについて解説し、実際に動くコードを書いてみます。

Contents
Webスクレイピングとは
Webスクレイピングとは、インターネットを通じてWeb上にある情報を自動で取得する技術のことです。
普段はブラウザを用いて、Googleなどの検索エンジンからWeb上の情報を収集します。Webスクレイピングを使えば、その作業を自動化することができます。
PythonでWebスクレイピングをする方法
PythonでWebスクレイピングをするための最も一般的な方法は、『request』と『BeautifulSoup』の2つのライブラリを使用することです。
- requestでHTTP通信を行い、Webサイトの情報(HTMLなど)を取得
- 取得した情報をBeautifulSoupで解析
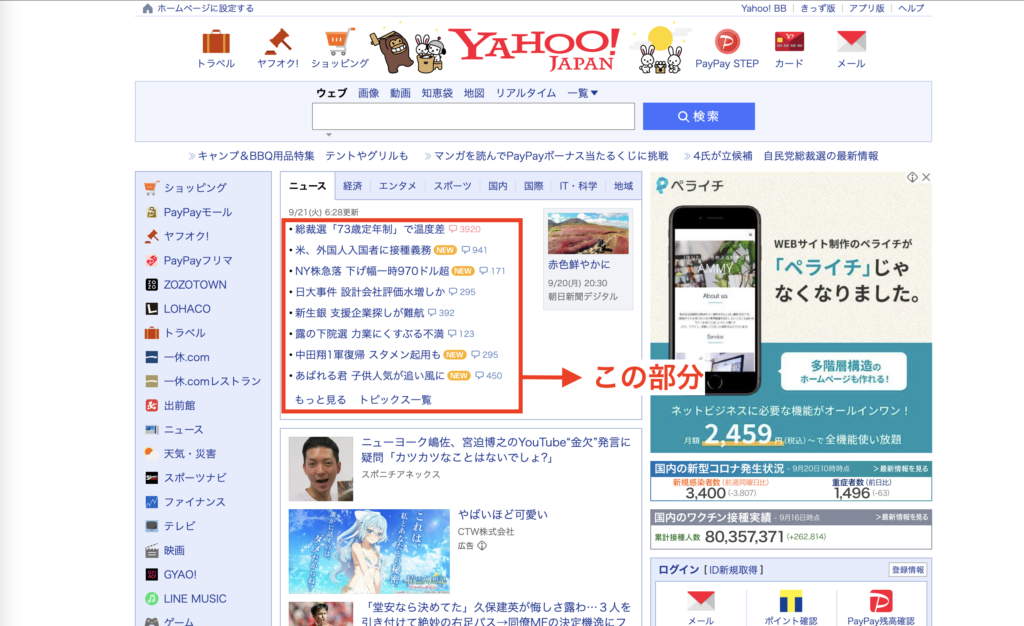
例えば、Yahoo!ジャパンのホームページから、ニュースのタイトルをスクレイピングで取得するコードは以下のようになります。
#ライブラリのインポート
import requests
from bs4 import BeautifulSoup
#requestsでYahooジャパンのホームページの情報を取得
r = requests.get('https://www.yahoo.co.jp/')
#BeautifulSoupに取得した情報を渡す
soup = BeautifulSoup(r.text, 'html.parser')
#HTMLのクラスを利用して、タイトルのHTMLを取得
yahoo_news_titles = soup.select('._3cl937Zpn1ce8mDKd5kp7u')
#タイトルのHTMLから文字だけを抽出
for title in yahoo_news_titles:
print(title.string)これを実行すると、以下の文字が出力されます。
総裁選「73歳定年制」で温度差
米、外国人入国者に接種義務
NY株急落 下げ幅一時970ドル超
日大事件 設計会社評価水増しか
服役した人らカメラで検知 JR東
新生銀 支援企業探しが難航
中田翔1軍復帰 スタメン起用も
あばれる君 子供人気が追い風にこのように、Pythonの2つのライブラリ、『requests』と『Beautifulsoup』を使うことで簡単にWebの情報をスクレイピングできてしまうのです。
ただし、PythonでWebスクレイピングをする方法はこれだけではありません。
WebスクレイピングができるPythonのライブラリ
PythonでWebスクレイピングをする方法はいくつかあります。ここでは有名な3つの方法を紹介します。
- BeautifulSoup
- Selenium
- Scrapy
この3つのライブラリが、スクレイピングやクローリングをするためによく使われるものです。
BeautifulSoup
これは先ほど紹介した通り、requestsと組み合わせて使用します。requestsでHTMLを取得して、BeautifulSoupでHTMLを解析するという流れです。
それでは実際にコーディングをしながらスクレイピングをしてみましょう。
ライブラリをインストールしていない場合は、pipコマンドでインストールしましょう。
pip install beautifulsoup
pip install requestsここでは改めて、Google newsの見出しをスクレイピングしてみます。
#ライブラリのインポート
import requests
from bs4 import BeautifulSoup
#Googleニュースのトップページの情報を取得
r = requests.get('https://news.google.com/topstories?tab=rn&hl=ja&gl=JP&ceid=JP:ja')
#取得した情報をBeautifulSoupに渡す
soup = BeautifulSoup(r.text, 'html.parser')
#HTMLのクラスでタイトルを取得
titles = soup.select('.ipQwMb')
#文字だけを抽出
for title in titles:
print(title.string)これの出力結果は以下の通りです。

ここでは簡単に解説いたします。
soup = BeautifulSoup(r.text, 'html.parser')について、r.textには、URLで取得したWebページの全 HTMLが詰まっています。これを『BeautifulSoup』の第一引数に、またHTMLのパーサーを第二引数で指定すれば、準備万端です。
『select』メソッドで取得したいタイトルのタグと紐づけられたHTMLのクラスを指定すれば、その要素だけを抽出できます。
クラスを確認するには、ブラウザの開発者ツールを用いてHTMLソースを表示します。Googleニュースのタイトルは以下のようなHTMLで構成されており、3つのクラスが付与されています。
このうち一つのクラス『ipQwMb』を選択して、BeautifulSoupで抽出しました。
<h3 class="ipQwMb ekueJc RD0gLb">
<a href="./articles/CBMiOGh0dHBzOi8vd3d3Lm1iYy5jby5qcC9uZXdzL2FydGljbGUvMjAyMTA5MjIwMDA1MTg5My5odG1s0gEA?hl=ja&gl=JP&ceid=JP%3Aja" class="DY5T1d RZIKme">MBCニュース | 鹿児島県がアストラゼネカワクチン接種へ 他社接種できない人など対象</a>
</h3>クラスで指定するとき、『.ipQwMb』とドットを直前につける必要があります。(CSSセレクタと同じルールですね。)
titles = soup.select('.ipQwMb')こうすることで、『.ipQwMb』のクラスを持つ要素を全て取得できます。なので、一つずつループを使って表示しているのです。
Selenium
これは、ブラウザを自動化するライブラリです。『検索』『クリック』などの動作を自動化することができるので、直感的にプログラムを作ることができます。
Seleniumでwebスクレイピングをするためには、Chromeドライバーをインストールする必要があります。
参考:ChromeDriver インストール方法【Mac】【Windows】
先ほどと同じく、Googleニュースの見出しをスクレイピングしてみます。
#ライブラリのインポート
from selenium import webdriver
#ブラウザを立ち上げる
browser = webdriver.Chrome()
#google newsを開く
browser.get('https://news.google.com/topstories?tab=wn&hl=ja&gl=JP&ceid=JP:ja')
#クラスでトップ記事の見出しを取得
top = browser.find_elements_by_class_name('ipQwMb')
#タイトルを表示
for title in top:
print(title.text)上のプログラムを実行すると、以下のようにGoogleニュースのトップページのタイトルが出力されます。

seleniumはブラウザの制御ライブラリなので、プログラムを実行するたびにいちいちブラウザが起動します。また、出力されるまでの実行時間が非常に長いです。
しかし、クリックや検索窓に文字を送り検索するなど、BeautifulSoupにはできないことがSeleniumではできてしまいます。
さらに詳しく:【Python】seleniumでwebスクレイピング
Scrapy
これは、スクレイピングやクローリングをするためのフレームワークです。よりプロ向け、大規模向けなライブラリなので本記事では紹介しきれません。
Scrapy is an application framework for crawling web sites and extracting structured data which can be used for a wide range of useful applications, like data mining, information processing or historical archival.
Scrapyは、Webサイトをクロールして構造化されたデータを抽出するためのアプリケーションフレームワークで、データマイニングや情報処理、過去のアーカイブなど、さまざまな有用なアプリケーションに利用することができます。
https://docs.scrapy.org/en/latest/intro/overview.html
と公式ドキュメントにもあるように、もはや一つのアプリケーションであり、クロールやスクレイピングするために必要な機能の全てが備わっています。
ぜひこちらの公式ドキュメントを見てみてください。
Pythonでスクレイピングをするときの注意点
以上のように、Pythonでwebスクレイピングする方法は様々です。しかし、他の誰かが運用しているWebサイトのサーバーと通信するという意味では全て同じです。
自動化は大変便利ですが、短時間で何度も通信するようなプログラムを書けば、対象のWebサイトのサーバーに負荷がかかります。そのため、webスクレイピングが禁止されている場合もあるので気をつけましょう。
禁止されていなくても、サーバーダウンや、最悪の場合(サーバー契約の種類によっては)相手のWebサイトが消えてしまうこともあり得るそうです。そんなことが起きないように、良識ある範囲でwebスクレイピングを楽しみたいですね。




