最近Kaggleでデータサイエンスの勉強をはじめました。機械学習を学ぶコースを終了したので忘れないようにアウトプットしておきます。

必要なライブラリのインポート
まだscikit-learnをインストールしていない場合は、pipでインストールしましょう。
pip install scilit-learnまず、機械学習を実装するために必要なライブラリをインポートします。
import pandas as pd #データ管理ライブラリ
from sklearn.ensemble import RandomForestRegressor #機械学習のモデル
from sklearn.metrics import mean_absolute_error #予測値と実際の値の差を比較
from sklearn.model_selection import train_test_split #訓練データと試験データを分割Pandasはデータをエクセルの表の様にして管理することができます。行・列から思いのままにデータを取り出して利用することができます。
RandomForestRegressorはscikit-learnが用意してくれている機械学習用のモデルです。
mean_absolute_errorは予想された値と実際の値の誤差を平均で算出してくれるモジュールです。
train_test_splitは訓練用のデータと予測用のデータを分割するためのモジュールです。
それでは実装していきましょう。初めての人にとっては結構驚きですが、超簡単です。
データを読み込む
ここではオーストラリアのメルボルンという世界都市の不動産物件の値段を予測します。
データはこちらから『melb_data.csv』をダウンロードします。ダウンロードしたら、Pythonファイル(ipynbファイル)と同じ階層に置きます。
そうしたら、Pandasのデータフレームとして読み込むことができます。
data = pd.read_csv('melb_data.csv')読み込まれたCSVは次のような構造をしています。
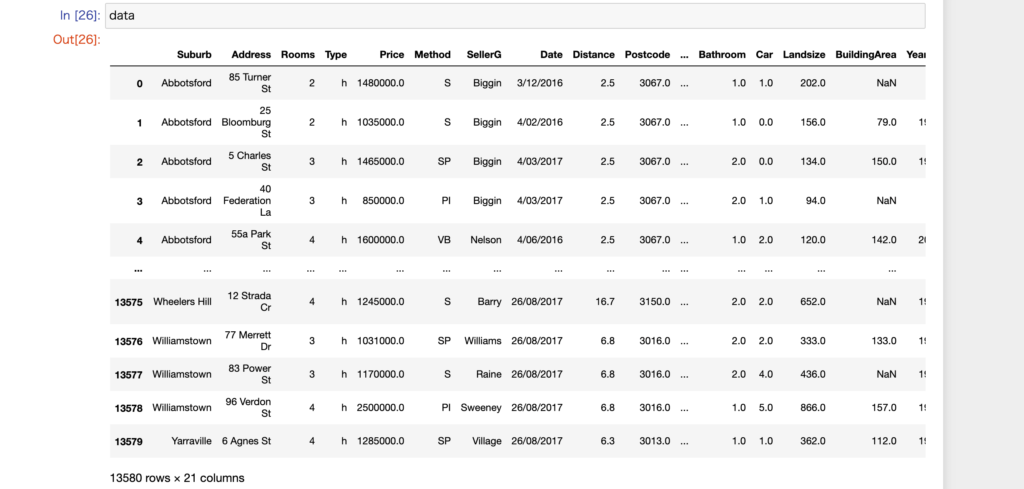
Suburb・・・地域、Address・・・住所、Room・・・部屋数、Price・・・値段、など物件の様々な属性を表で見ることができます。
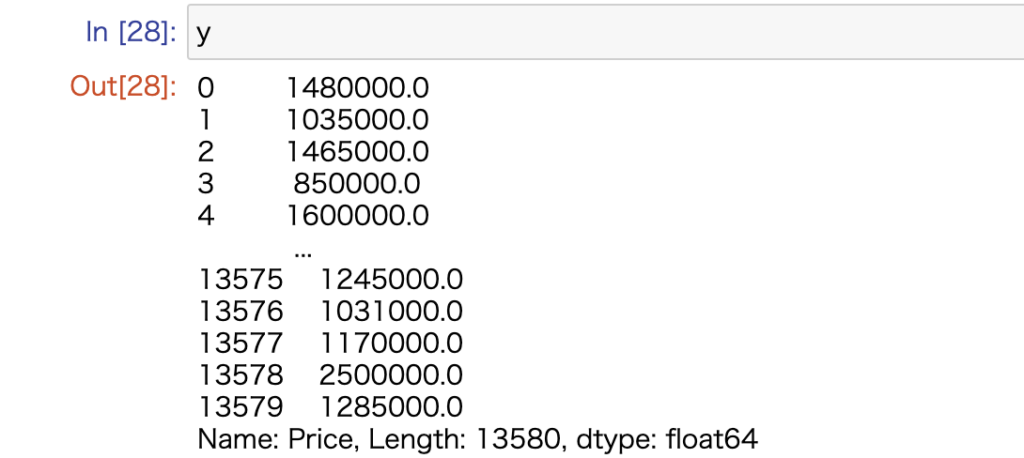
ここで予測したいのは値段、Priceです。yという変数に格納します。
y = data.Priceyは次の様な構造をしています。
そしてその値段を決定しているであろう要素を自分で抽出しなくてはなりません。ここでは21項目のうち、次の5つの項目を抽出します。
- Room・・・部屋数
- Bathroom・・・トイレの数
- Landsize・・・土地面積
- Lattitude・・・緯度
- Langtitude・・・経度
全部の項目を確認するためには、dataのcolumns属性を呼び出します。
data.columns
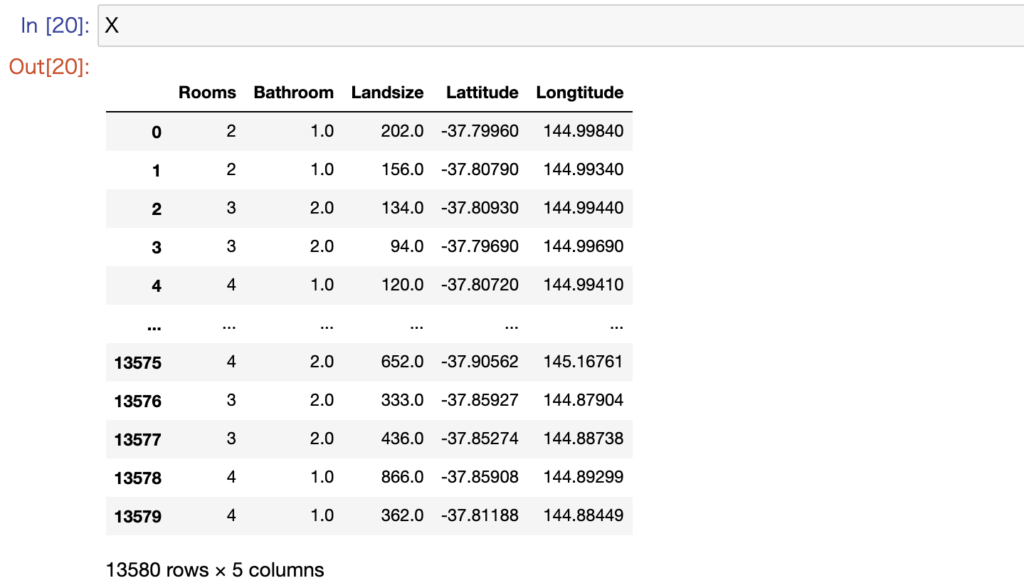
先程の5つの項目のデータを抽出します。
features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude']
X = data[features]すると新たに作成されたデータフレームXは次の様な構造をしていることが確認できます。
機械学習の訓練用と予測用のデータを分割する
不動産物件の価格を決めるであろう要因と、価格をそれぞれX, yの変数に格納しました。ここから、学習用のデータと予測に使うデータに分割します。
学習用のデータを、train_X, train_y、とし、予測用のデータをval_X, val_yとしましょう。これを綺麗に分割してくれるモジュールは先程インポートしました。『train_test_split』です。
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state=1)とすることで、それぞれの変数にデータを分割して格納することができます。
ここで重要なのは、指定する変数(train_X, val_X, train_y, val_y)と渡す引数(X, y)の順番です。
また、random_stateでは、ランダムにデータを分割するのですが、そのパターンを指定することができます。別に0でも1でも2でも問題はありませんが。
ここでtrain_Xがどのような構造になっているのか確認してみましょう。
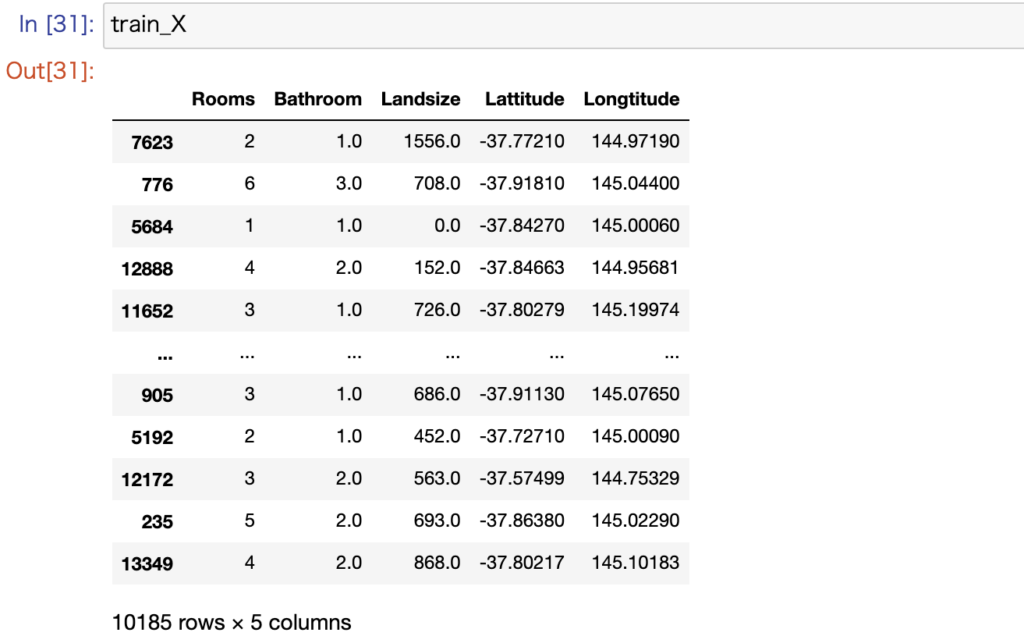
良い感じに分割され、かつランダムな配置になっていることが確認できます。元のデータの75%が訓練用のデータになっていることがわかります。
モデルを用いて予測をする
scikit-learnには多くの予測モデルがありますが、ここでは初学者にはテンプレのRandomForestRegressorを用いて機械学習をします。
このモデルではdecision tree(決定木)を何個もランダムに作り出し、それぞれの決定木が予測する値を平均して予測値とします。
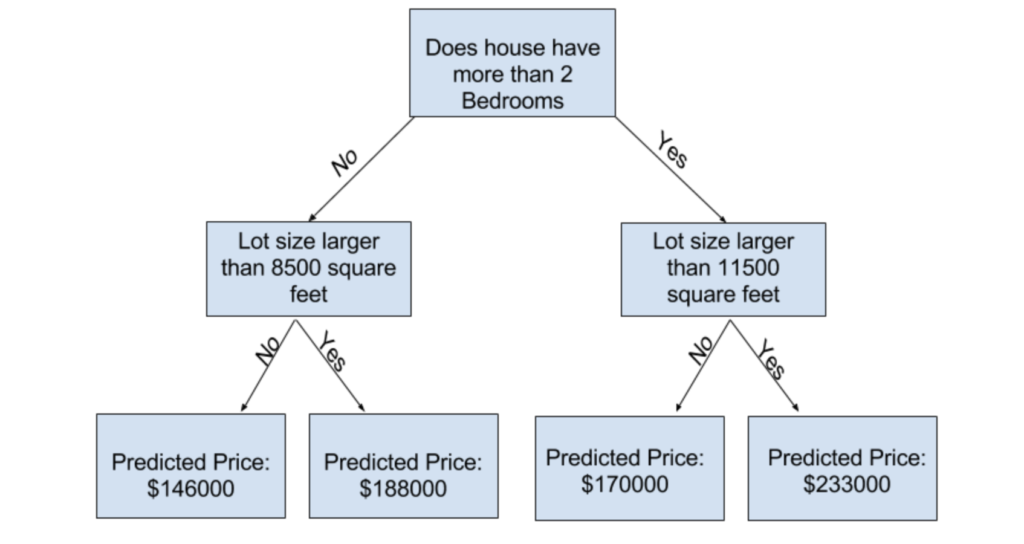
機械学習のモデルを立てるとき、それについてよく知っている必要があると思いますが、scikit-learnでは何も知らなくても実装できてしまいます。
model = RandomForestRegressor(random_state=1) #モデルを定義
model.fit(train_X, train_y) #モデルに学習させる
prediction = model.predict(val_X) #モデルに予測をさせるモデルを定義し、学習用のデータを与え、予測用のデータを渡す。
立ったのこれだけで機械学習の実装ができてしまいます。変数predictionには予測された不動産物件の価格が配列として格納されています。

あとは、実際の価格(val_yに格納されている)と比較してどの程度正確に予測できているか確認するだけです。
予測された結果を評価する
いよいよ最後の段階です。ここで予測された結果を評価しましょう。
予測された物件の一個めの価格は『2150140』でした。しかし実際の価格は『1800000』です。つまり『350140』の誤差(20%)があるわけです。予測と実際の値にどれぐらい差があるのか、絶対値で平均を算出してくれるのが『mean_absolute_error』です。
mae = mean_absolute_error(prediction, val_y)
print("実際の価格とのずれは{:,.0f}です。".format(mae))すると次の様な出力が確認できるはずです。

最後に
機械学習は、scikit-learnを用いれば簡単に実装できます。その予測のモデルを知らなくてもできてしまうのです。
ただし、予測の精度を向上させるためにはいろいろなモデルを勉強する必要がありますし、どの様な場合にどの様なモデルを適応できるのかは結構シビアだったりします。
簡単な機械学習から初めて、徐々にモデルについて調べ、スキルをあげていきたいものです。